
在制定企业数据管理策略时,数据存储与架构选型是首要决策。传统企业需在结构化数据仓库与原始数据湖之间二选一,而 AI 技术的普及,让数据平台不仅要支撑报表与 BI 分析,还要适配实时处理、非结构化数据与 AI 应用,数据湖屋这种融合型架构由此成为主流选择。
本文将清晰拆解数据仓库、数据湖、数据湖屋的核心定义、差异、适用场景,帮你快速确定适合企业的数据架构。
一、三者核心概念速览
- 数据仓库:存储结构化、预处理后的数据,专为商业智能、报表分析优化,查询速度快、数据治理能力强。
- 数据湖:可海量存储原始结构化 + 非结构化数据,存储灵活易扩展,适合数据科学探索与机器学习建模。
- 数据湖屋:融合前两者优势,在数据湖存储基础上,叠加治理、模式管理与高性能查询,同时支撑 BI 分析与 AI 工作负载。

请保存信息图,快速参考数据仓库、湖泊和湖屋之间的区别及其使用时间
二、什么是数据仓库?
数据仓库是集中式分析数据库,专门存储清洗、结构化处理后的数据,核心面向报表与商业智能场景。
可以把它比作规整的图书馆,数据已完成分类、整理、标注,用户可快速查询获取结果,比如快速统计 “上月退货总量” 这类业务问题。
核心特征
- 中央存储库:覆盖企业全部门数据,简化跨部门查询流程。
- 多源数据整合:接入事务数据库、CRM、ERP、日志文件等多种数据源。
- 历史数据留存:存储长期历史数据,支撑趋势分析。
- 结构化集成:按预定义模式组织数据,适配分析查询。
- 面向主题、非易失性:聚焦销售、客户等业务主题,数据写入后不可随意修改删除。
主流云数据仓库
雪花、谷歌 BigQuery、亚马逊红移、Azure Synapse。
数据构建与管道
传统构建采用ETL(提取 – 转换 – 加载) 流程,先清洗转换数据再入库;现代云仓库也支持 ELT 模式,先加载数据再通过计算引擎转换。
仓库内还会细分数据集市,针对销售、财务、营销等单一业务领域,提供轻量化数据子集。
核心优势
数据预处理完成,分析师可快速搭建报表与仪表盘,适合跨部门重复使用的标准化指标分析;但前期需投入大量数据准备与工程工作。
三、什么是数据湖?
数据湖是高可扩展存储系统,可保留各类数据的原始格式,无需提前预处理,支持海量低成本存储。
可存储数据类型
- 结构化数据:关系型数据库数据
- 半结构化数据:CSV、JSON、XML
- 非结构化数据:邮件、文档、PDF
- 二进制数据:图片、音频、视频
主流存储方案
亚马逊 S3、Azure 数据湖存储、谷歌云存储(对象存储)。
工作原理
采用ELT(提取 – 加载 – 转换) 流程,直接将原始数据导入存储,后续按需提取转换,无需提前定义数据模式。
核心特征
- 全类型数据存储:兼容结构化、半结构化、非结构化、二进制数据。
- 开放格式:避免技术绑定,扩展性极强。
- 数据目录完善:通过元数据仓库管理数据位置与结构,消除数据孤岛。
- 资源高效:依托对象存储,低成本承载海量数据。
核心优势
灵活性拉满,无需预处理即可快速存数,前期成本更低;但未治理的数据湖易沦为数据沼泽,且报表分析需重新计算指标,耗时较长。
适合数据战略未明确、需快速归集海量数据、开展数据实验的企业。
四、什么是数据湖屋?
数据湖屋是融合数据湖与数据仓库优势的新型架构,以开放格式存储对象数据,同时叠加仓库级的数据管理与性能能力。
核心增强能力
- 支持 ACID 事务
- 实现模式执行
- 提供索引与性能优化
- 具备数据版本与时间旅行功能
分析工作负载可直接在数据湖存储上运行,无需复制数据到仓库,一套架构同时支撑 BI 与 AI。
主流技术与平台
Databricks 湖屋、三角洲湖、阿帕奇冰山、阿帕奇胡迪,主流云平台均已适配该架构。
核心优势
解决传统 “湖 + 仓” 分离导致的数据冗余、流水线复杂问题,统一支撑批处理分析、流式数据管道、AI / 机器学习、大规模数据探索,是适配 AI 时代的主流架构。
五、AI 如何重塑数据架构?
AI 技术让数据架构从报表驱动转向智能应用驱动,带来三大核心转变:
- 从 BI 平台到 AI 数据平台:从单纯支撑报表,升级为支持机器学习、特征工程、实时预测。
- 从结构化到多模态数据:AI 依赖文本、图像、音视频等非结构化数据,推动湖、湖屋架构普及。
- 从批处理到实时处理:推荐系统、欺诈检测等 AI 场景,需要低延迟流式数据处理。
同时,AI 也为数据栈新增组件:特征库、向量数据库、进阶数据治理体系,让数据工程、分析、机器学习融合为统一平台。
六、现代数据架构:不止于存储
现代数据平台会结合多种架构理念,突破单一存储局限:
- 流式数据管道:通过卡夫卡、Spark Streaming 等技术,实现实时数据处理,支撑实时仪表盘。
- 数据网格:去中心化数据所有权,按业务领域划分数据产品,搭配自助式基础设施与统一治理。
- 语义层:集中定义业务指标,确保全平台 KPI 口径一致。
七、企业如何选型?
没有绝对最优架构,需结合企业分析需求、数据战略、治理要求、AI 应用场景决策,多数企业采用混合方案:
- 选数据仓库:核心需求是 BI 报表、标准化业务指标,用户以结构化数据分析师为主,AI 场景较少。
- 选数据湖:需归集海量原始数据、开展机器学习实验,数据模式频繁变动,追求灵活存储。
- 选数据湖屋:需要统一平台支撑 BI 分析与 AI 工作负载,希望减少数据冗余,适配实时数据处理。
像 KNIME中文版 这样的工具帮助组织在数据仓库、数据湖和湖屋环境中构建和协调数据流水线。
八、KNIME 如何支持 ETL 和 ELT 流程
KNIME 是一个无需编码即可访问、混合、分析和可视化数据的平台。
KNIME 提供了一个可视化界面,用于构建支持 ETL 和 ELT 架构的数据管道。
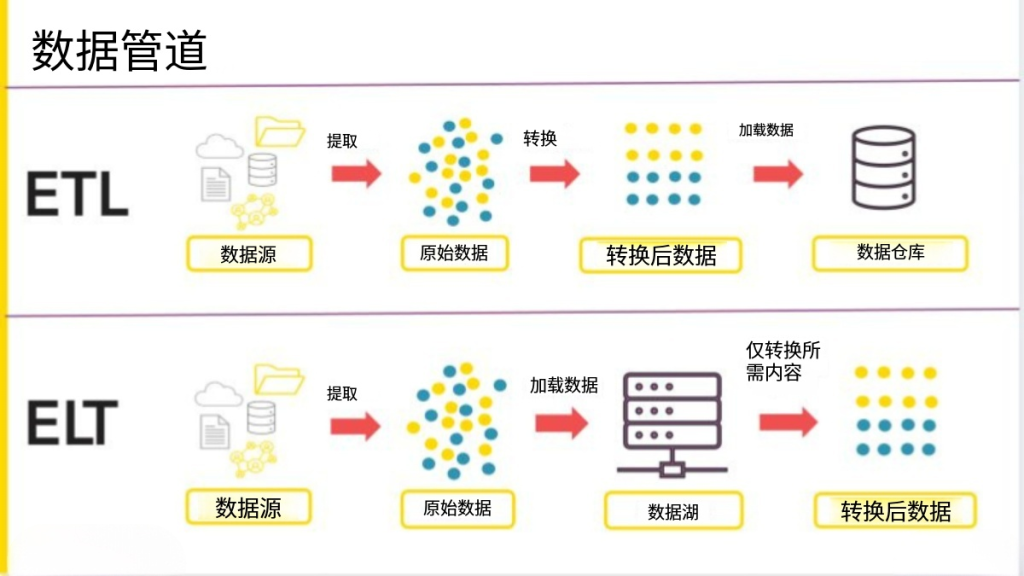
ETL 与 ELT
通过 KNIME中文版,你可以轻松:
- 连接所有类型的数据源
- 组装自动化数据流水线,用于 ETL 和 ELT 流程
- 集成云数据仓库和数据湖
- 为你的业务需求实施必要的指标。
KNIME 提供 300+ 接口,用于交互:
- SQL 数据库
- NoSQL 系统
- 云存储
- 大数据平台
- 网络服务等。
KNIME中文版 的灵活性意味着你可以无缝使用数据仓库、数据湖和湖屋平台。
九、常见问题解答
- 数据湖能替代数据仓库吗?
不能,二者定位不同:数据湖存原始数据,数据仓库存预处理数据,可共存互补。KNIME中文版可实现二者的数据联动,让原始数据经过转换后同步至数据仓库,支撑多场景分析。 - 数据湖和数据仓库谁更快?
数据仓库查询更快(数据已预处理),但入库耗时久;数据湖入库简单,查询分析需额外转换,速度较慢。KNIME中文版可通过优化数据转换流程,缩短数据湖的查询耗时,同时简化数据仓库的入库操作。 - 什么是数据集市?
数据仓库的轻量化子集,专为单一部门 / 业务职能设计,比如营销数据集市、财务数据集市。KNIME中文版可对接数据集市,按需生成部门专属报表。 - 数据仓库层是什么?
数据处理的全阶段,包含数据源层、临时存储层、ETL 层、存储层、访问层、元数据层。KNIME中文版可覆盖数据仓库各层的操作,实现数据处理全流程的可视化管理。
十、总结
数据仓库适配标准化 BI 分析,数据湖适配灵活存储与数据探索,数据湖屋则统一支撑分析与 AI,成为现代企业数据平台的优选。选型核心不再是 “选湖还是选仓”,而是如何让数据分析与 AI 应用高效协同,匹配企业长期数据战略。
而KNIME中文版作为一款灵活高效的数据工具,可无缝融入三种架构,简化数据流水线搭建,降低技术门槛,帮助企业快速落地数据管理与分析需求,实现数据价值的最大化。





